LLM笔记1:了解大模型的历史及特点
本文最后更新于:2023年11月20日 凌晨
1、概述
1.1、词义解惑
部分专业名词缩略词表:
| 缩写 | 全称 | 说明 |
|---|---|---|
| LLM | Large Language Model | 大语言模型:参数量达到10亿级别以上的(不同领域定义会存在偏差) |
| PLM | Pre-trained Language Model | 预训练语言模型:这种模型是在大规模文本数据上进行预训练,然后可以通过微调或其他技术来适应特定的自然语言处理任务。常见的PLM包括BERT、GPT等。 |
| AGI | Artificial General Intelligence | 通用人工智能 |
1.2、关于大模型LLM的认识
现如今LLM(大语言模型)发展迅速,在各种应用领域都有不错的应用效果,如在自然语言处理领域,LLM可以帮助计算机更好地理解和生成文本,包括写文章、回答问题、翻译语言等。在信息检索领域,它可以改进搜索引擎,让我们更轻松地找到所需的信息。在计算机视觉领域,研究人员还在努力让计算机理解图像和文字,以改善多媒体交互。下面来了解一下语言模型的发展历程。
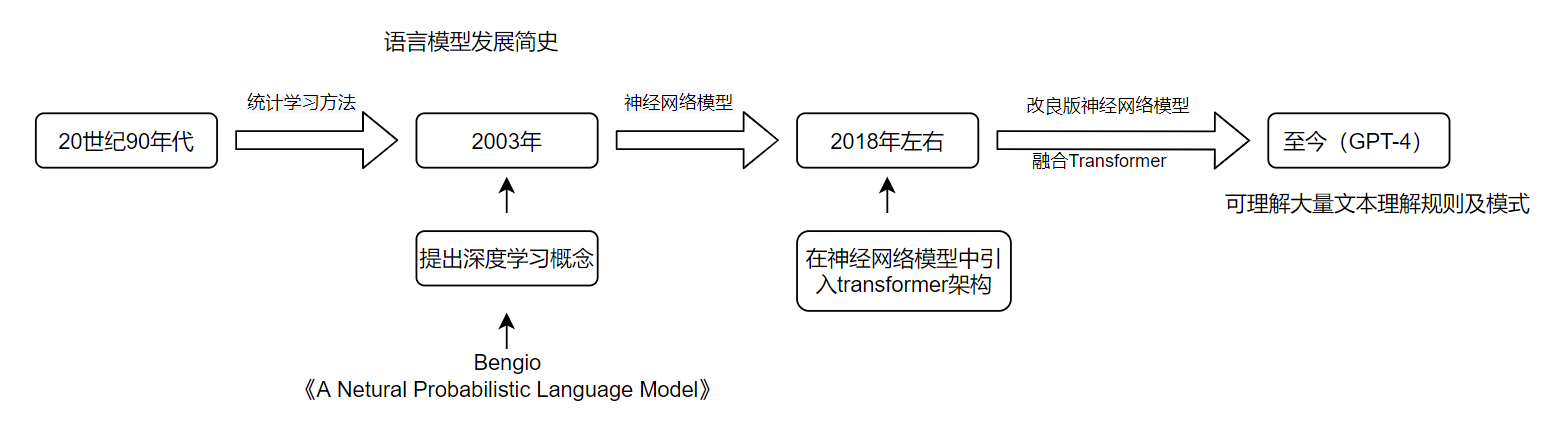
2、语言模型发展简史
梳理的一张发展简图:
3、国内外的LLM发展
3.1、大模型的发展
2019年大模型开始进入爆发式发展,至今在各大科技公司或研究机构已有非常多的LLM落地实现。下面是按时间线【2019年 - 2023年 6月】列出的LLM发展轨迹,其中仅包含模型参数量超100亿的大模型,如下图所示:
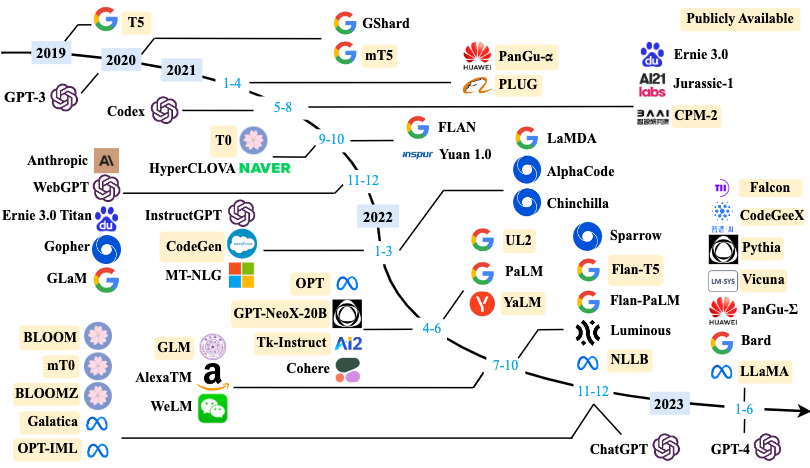
图来源于:https://arxiv.org/abs/23018223
3.2、国外代表性LLM大模型
3.2.1、开源模型
| LLM名称 | 参数量 | 上下文长度 | 发布厂商/研究机构 | 开源地址 |
|---|---|---|---|---|
| LLaMA系列 | 70亿-650亿 | 32k-256k | Meta | https://github.com/facebookresearch/llama |
3.2.2、闭源模型
国外现如今的LLM发展很迅速,在继OpenAI发布ChatGPT之后,各大厂商纷纷推出自己的大语言模型,具有代表性的LLM如下:
| LLM名称 | 参数量 | 上下文长度 | 发布厂商/研究机构 | 发布时间 | 学习知识库截止日期 |
|---|---|---|---|---|---|
| GPT-4 Turbo | 未公布 | 128k | OpenAI | 2023 年 11 月 7 日 | 2023 年 4 月 |
| GPT-4 | 1.8 万亿(猜测) | 未公布 | OpenAI | 2023 年 3月 | 2021 年 9 月 |
| GPT-3.5 | 1750亿 | 16k | OpenAI | 2023 年 3月 | 2021 年 9 月 |
| Claude 2 | 860.1 亿(猜测) | 200K | Anthropic 公司 | 2023 年 7 月 11 日 | 2022 年 11 月 |
| Claude | 62亿 | 100K | Anthropic 公司 | 2023 年 3 月 15 日 | 2022 年 3 月 |
| PaLM 2 | 34亿 | 未公布 | 2022 年 5 月 | 未公布 |
3.3、国内代表性LLM大模型
3.3.1、开源模型
| LLM名称 | 参数量 | 上下文长度 | 发布厂商/研究机构 | 开源地址 |
|---|---|---|---|---|
| GLM系列 | 62 亿 | 2k | 清华大学&智谱 AI | https://github.com/THUDM |
| 通义千问(Qwen) | 70亿(7B)&140亿(7B) | 8k | 阿里巴巴 | https://github.com/QwenLM/Qwen/tree/main |
| Baichuan系列 | 70 亿 | 4k | 百川智能 | https://github.com/baichuan-inc |
| Yi | 60亿&340亿 | 200k | 零一万物 | https://github.com/01-ai/Yi |
3.3.2、闭源模型
| LLM名称 | 参数量 | 上下文长度 | 发布厂商/研究机构 | 发布时间 | 学习知识库截止日期 |
|---|---|---|---|---|---|
| 文心一言(4.0) | 2600 亿 | 未公布 | 百度 | 2023 年 3 月 | 未公布 |
| 星火大模型 | 1700 亿 | 未公布 | 科大讯飞 | 2023 年 5 月 6 日 | 未公布 |
4、LLM可能的应用场景
目前在LLM方面的应用,最多的便是Chat机器人,通过与人类对话的形式,理解人类指令和执行各种复杂任务。这一形式,大大的扩展了人们的想象空间,基于LLM的能力,可以让其充当各种角色来与自己对话,并可作为一个领域专家来回答或解决自己所提出的问题,当然目前这种对话形式以文字较多,后续会逐渐扩展到其他各种输入类型,如视频、语音、图像等等内容,并且在多模态领域也已有各种相对成熟的模型来调用,如GPT-4与DALL·E 3的联合,扩展了ChatGPT在图像生成方面的能力,未来的应用范围必定会非常的广泛。
5、我们如何利用LLM构建应用?
5.1、思考
在上述介绍了非常多的大语言模型,各有千秋,那么除了使用原生的Chat应用,我们还能够使用它们来做什么?目前大模型能够执行各种任务,代码编写、求解数学问题、写作建议、图像生成、摘要总结、搜索信息等等。那么这些能力,我们是否可以通过这些惊奇的能力来拓展应用的使用场景或者自定义应用的能力,那么我们如何来通过LLM来构建出我们自己的应用?在这个问题上,目前已经有了一个相对稳定的一个开发框架——LangChain。LangChain为开源工具,
为了将大模型整条链路能够部署在端侧,即部署为应用,这个工具实现了将整个链路连接在一起,可以更便捷的开发上层应用,在制作自己专属的LLM应用上更为的简单。
5.2、LangChain
LangChain是一个用于开发由语言模型驱动的应用程序的框架,可以将不同的LLM模型、向量数据库、交互层 Prompt、外部知识、外部代理工具等工具前部整合到一起,进而方便我们可以自由构建专属LLM应用。
相关资源:
Langchain官网:https://www.langchain.com/
中文官方文档:https://www.langchain.asia/
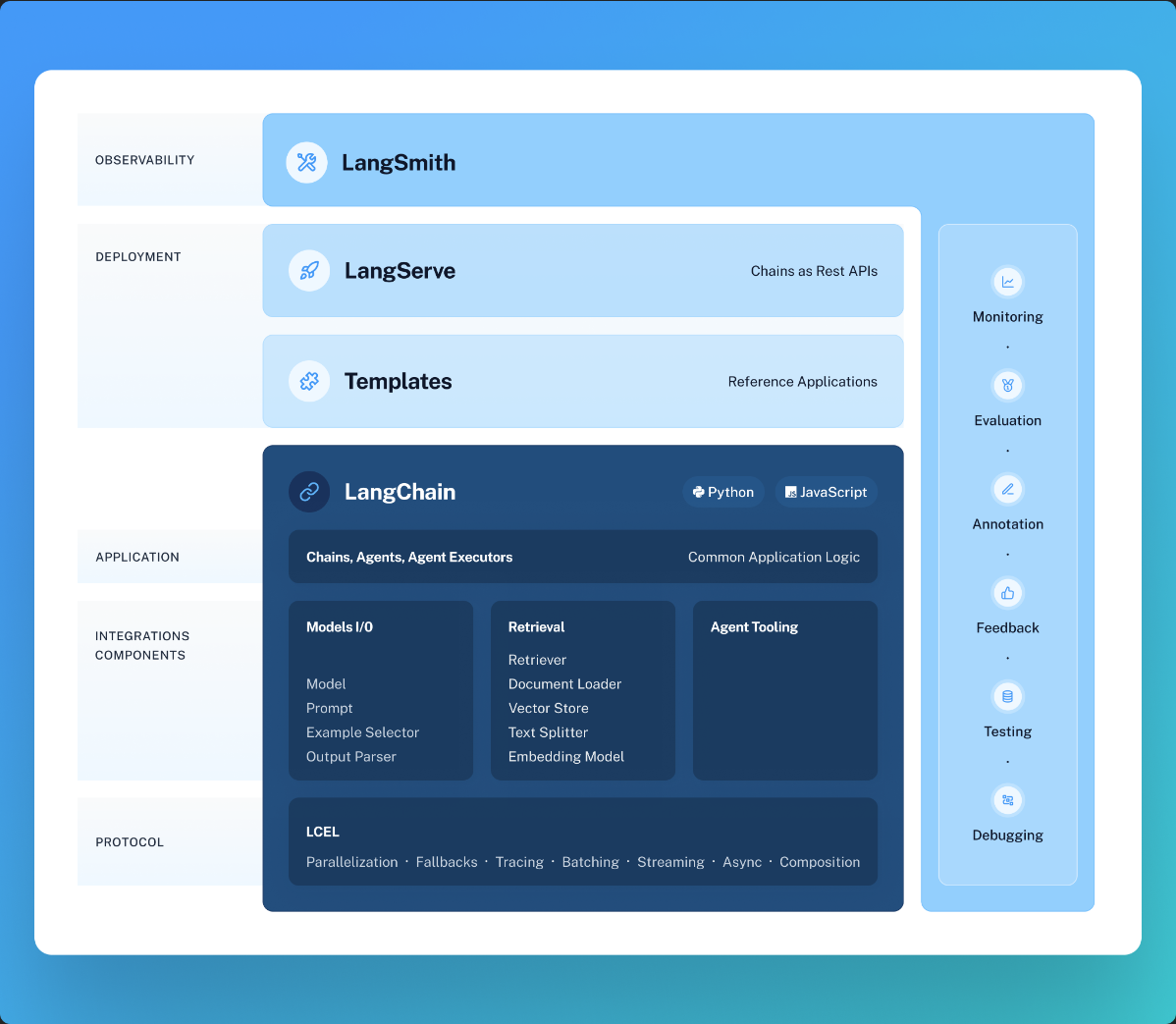
框架由几个部分组成:
LangChain 库:
Python 和 JavaScript 库。包含无数组件的接口和集成,将这些组件组合成链和代理的基本运行时,以及链和代理的现成实现
LangChain模板:
一组易于部署的参考架构,适用于各种任务
LangServe:
用于将LangChain链部署为REST API的库
LangSmith:
开发者平台,可调试、测试、评估和监控基于任何LLM框架构建的链,并与LangChain无缝集成
基本的结构图如下:
参考:
1)https://python.langchain.com/docs/get_started/introduction
2)https://datawhalechina.github.io/llm-universe/#/C1/4.%20%E4%BB%80%E4%B9%88%E6%98%AF%20LangChain