本文最后更新于:2023年11月20日 凌晨
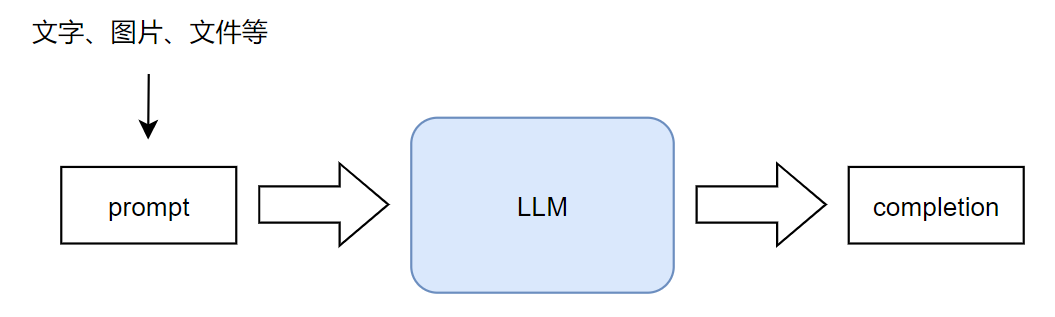
1、Prompt认识 1.1、Prompt基本概念 关于LLM大模型,在前面已经有了了解,现在来了解一下什么是prompt。在LLM发展早期,prompt是一个被用来给LLM下发任务的模板,每种分类任务或聚类任务对应一种prompt,当然不局限于此。随着LLM技术的发展以及ChatGPT的诞生,prompt已经泛指为给大模型的所有输入内容,不仅限与文字。我们与LLM的每次对话,都可视为一个prompt,而经过LLM输出的结果,称其为Completion 。简单点理解,输入即为prompt,输出即为completion。
1.2、Prompt中的常用参数
Temperature: 生成结果的随机性
参数范围:[0 ,1]
当temperature = 0时,LLM的创造性最低,生成的结果更加的保守 ,可预测,适用于一些对结果准确度或格式要求很高的场景。
当temperature = 1时,LLM的创造性最高,生成的结果更加的随机 ,难以预测,适用于一些更需要创造力的场景,如写作,设计等。
system prompt:
prompt中优先级更高的一种prompt,在一次完整的对话中,只会生效一个 system prompt ,如果一个对话中出现两个system prompt,则生效的为后者。system prompt的的主要作用是提前设定好LLM所扮演的角色或者预先的条件,这样在后续的输入中能够按照这个要求来给出更准确或更契合场景的回答。效果主要是用来提升用例体验,ChatGPT API开放后这概念被大量推广。不得不说,效果很好。
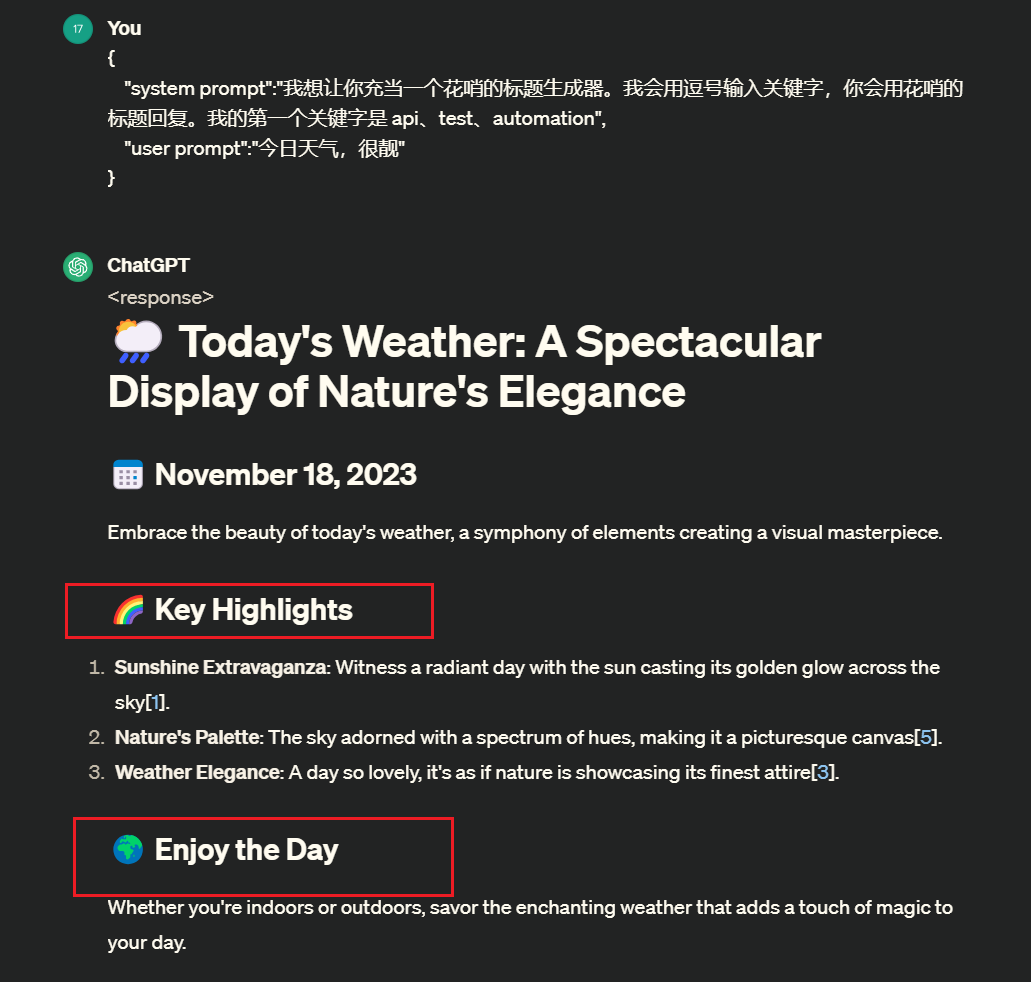
使用示例:
1 2 3 4 {
使用效果,确实会生成花里胡哨的标题
注: 这里所支持的角色可以根据自己的想法来设定,它所能做的能力范围有多大,全靠你想像有多大,能力不是无限大,在允许范围内尝试
user prompt:
prompt中的另一种:user prompt,等价于我们正常的输入,它的优先级会比system prompt优先级更低,如上述的示例,其中”今日天气,很靓”便是一个user prompt。区别在于,我们在一段完整对话中,可以迭代很多个user prompt,但system prompt只能有一个。
2、环境准备 2.1、Anaconda安装 Anaconda官网 下载安装包:
之后双击安装程序,修改安装路径之后按照推荐设定安装即可,此处不详述。
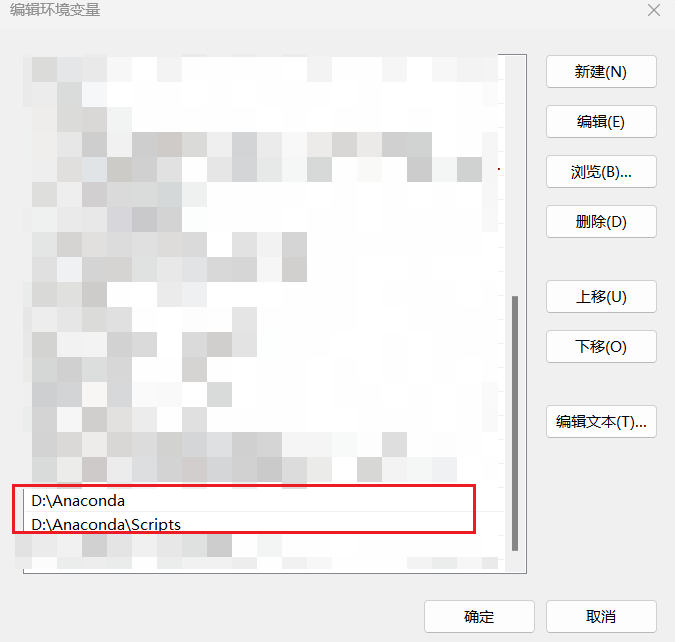
安装完成后,将anaconda中的Python配置到系统环境变量path中:添加两条环境变量路径如下,D:\Anaconda为我本地安装的路径
2.2、工具pip-search安装 pip-search可以用来查找指定的包:
1 2 3 4 5 pip install pip-search -i https://pypi.tuna.tsinghua.edu.cn/simple/# 搜索指定包 # 查看可安装包版本
2.3、pip必要库安装(Windows) 获取库依赖文件:https://github.com/datawhalechina/llm-universe
在仓库根路径下执行:
1 2 3 4 # 先cd 到仓库根路径 # 这里可能会涉及到修改pip的情况,使用Python进行安装
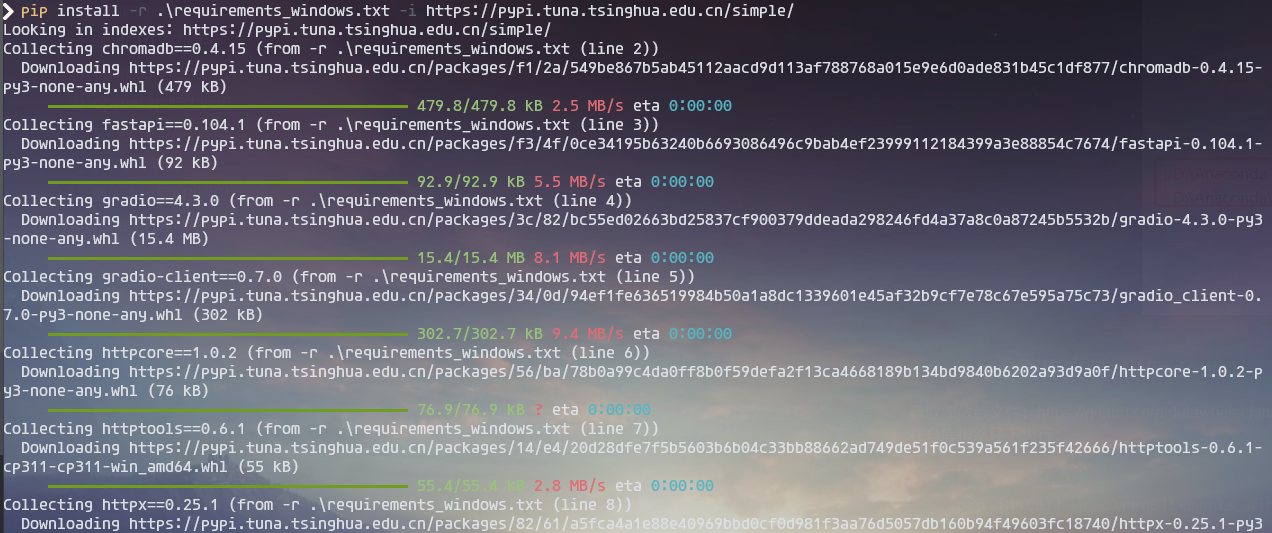
正常执行如下:这里我更改为了国内的清华pip源镜像下载
接下来就是等待其安装好,大约需要2-3分钟左右。
正常情况不会出现其他报错会直接安装成功,如下:
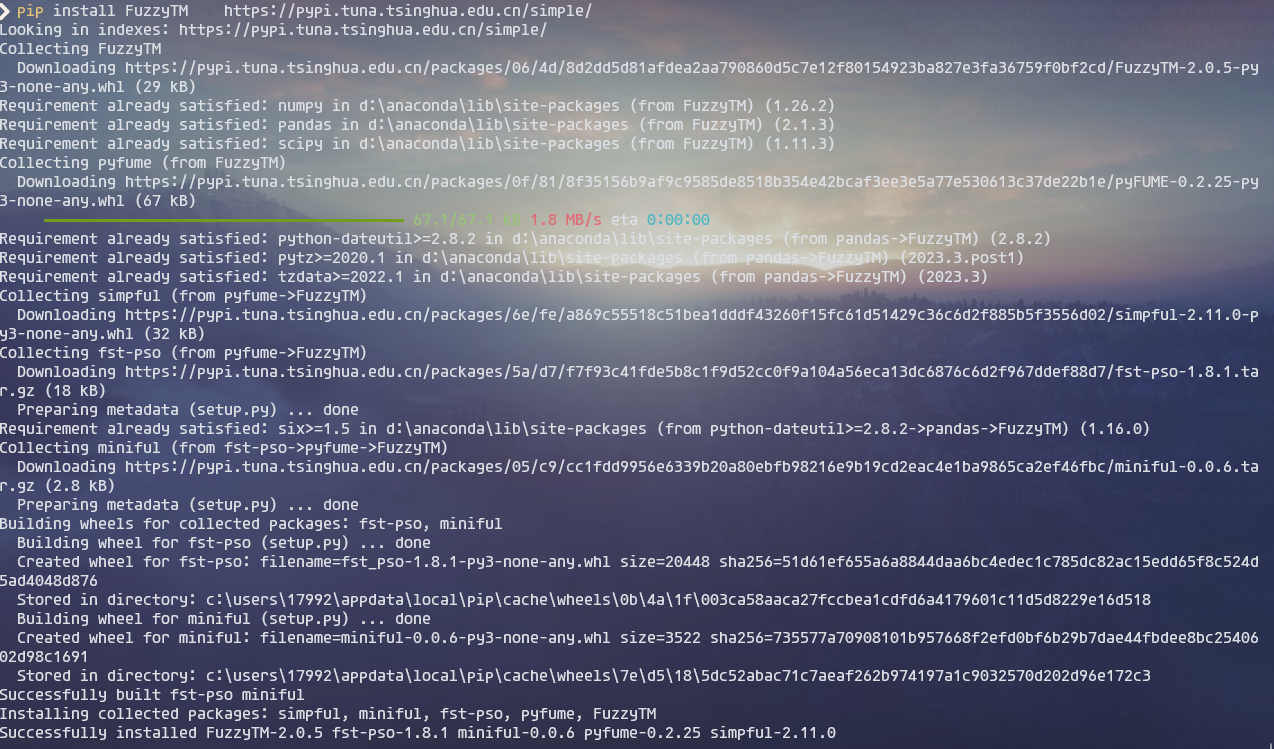
我这边安装出现了一些兼容性或缺包问题:
1 2 3 4 5 6 ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
逐个解决:
1 2 3 4 5 6 7 8 9 10 11 12 # 1、缺失FuzzyTM>=0.4.0 # 2、缺失blosc2~=2.0.0:指定下载2.0.0版本blosc2(先执行3,再执行这一步) # 3、缺失cython>=0.29.21 # # pip install pydantic==1.10.3 -i https://pypi.tuna.tsinghua.edu.cn/simple/ # 5、要求numpy<1.25,>=1.21 # 检查安装的版本,不满足则仿照步骤2,指定版本重新安装,pip index versions numpy查看可安装的版本
FuzzyTM安装:
cython安装:
blosc2 2.0.0版本安装:
pydantic库影响的是anaconda-cloud-auth 0.1.3,anaconda云授权库,可选的库有下面这些:(1.10.13安装后会出现不满足gradio库的现象,暂不处理,不影响后续代码运行)
numba安装:
2.4、pycharm创建项目 打开pycharm,NEW PROJECT,填写项目基本信息,选取本地安装的Anaconda中的Python:
3、LLM API的使用 3.1、ChatGPT API调用 1)OpenAI key生成 进入Overview页面:https://platform.openai.com/docs/overview
填写key名称,点击Create secret key之后生成相应的密钥:
生成后,拷贝生成的密钥,保存好密钥,后面会使用到它,注意密钥只会展示1次,关闭弹窗之后不会再显示 。生成成功之后会在API keys页面上展示刚才新建的key。一个免费账号密钥用量有效期在3个月 ,超过这段时间则无效。
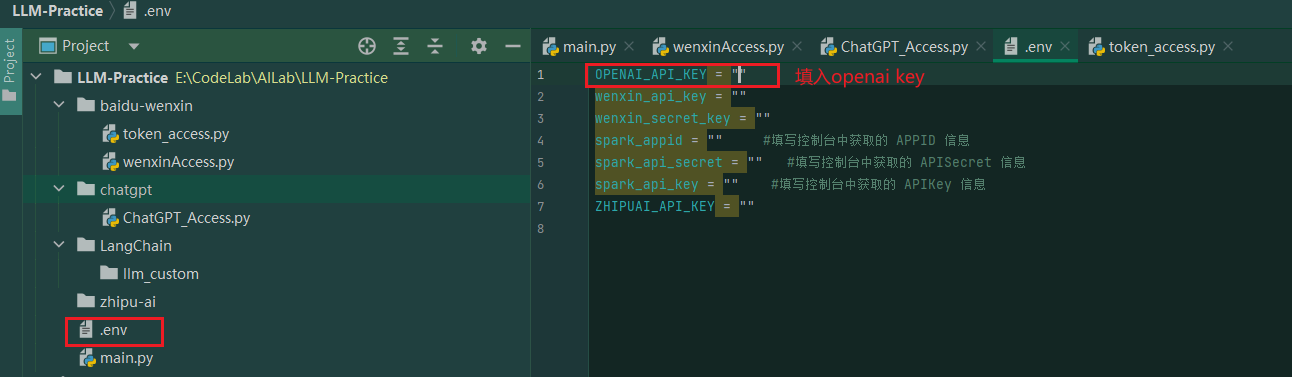
2)配置读取key 在项目根路径,创建.env文件保存我们的key
通过下面的代码来读取.env中的key值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import osimport openaifrom dotenv import load_dotenv, find_dotenvdef get_dotenv ():'HTTPS_PROXY' ] = 'http://127.0.0.1:9981' "HTTP_PROXY" ] = 'http://127.0.0.1:9981' 'OPENAI_API_KEY' )print (openai.api_key)return os.getenv('OPENAI_API_KEY' )
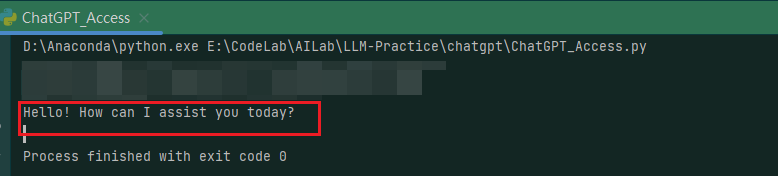
3)ChatGPT原生接口调用 获取到OpenAI官方的key之后,我们来尝试调用ChatGPT,参考官方文档 。:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import openaifrom obtain_key import get_dotenv"gpt-3.5-turbo" ,"role" : "system" , "content" : "You are a helpful assistant." },"role" : "user" , "content" : "Hello!" }print (completion["choices" ][0 ]["message" ]["content" ])
接口会返回一个ChatCompletion对象,包含了回答文本,创建时间等属性内容,我们仅需要content属性内容,返回示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # 完整的ChatCompletion对象
4)封装请求API函数 将API的调用进行封装:隐去了message的具体细节,并将模型固定,用户只需要传入prompt即user prompt的内容就行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def get_completion (prompt, model="gpt-3.5-turbo" , temperature = 0 ):''' 调用CHATGPT prompt: 对应的提示词 model: 调用的模型,默认为 gpt-3.5-turbo(ChatGPT),有内测资格的用户可以选择 gpt-4 ''' "role" : "user" , "content" : prompt}, {"role" : "system" , "content" : "You are a joyful assistant." }]return response.choices[0 ].message["content" ]
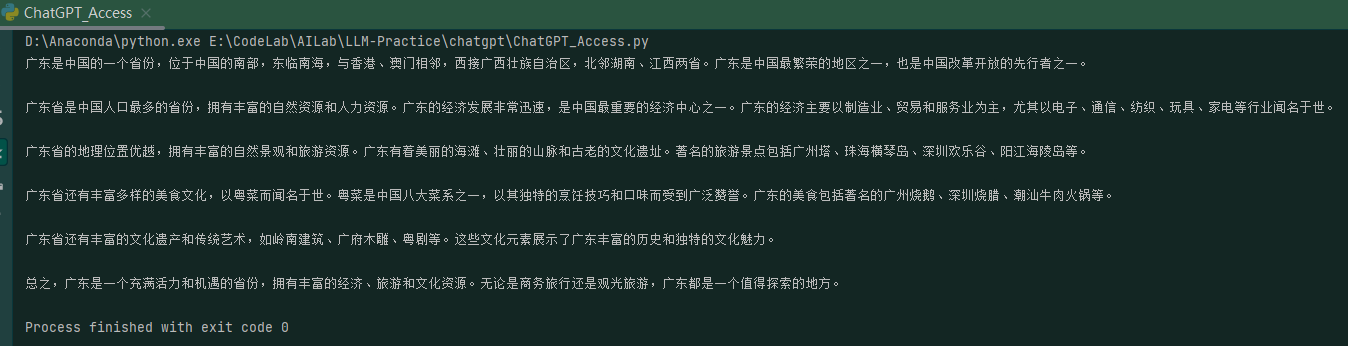
调用接口如下:
1 2 3 "介绍一下广东这个省" )print (completion)
5)使用LangChain调用ChatGPT LangChain中已经对ChatGPT进行封装,可以直接在应用中调用。更多细节,参考LangChain官方文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 """ langchain 调用 chatgpt """ from langchain.chat_models import ChatOpenAIimport osfrom obtain_key import get_dotenvprint (key)0.0 , openai_api_key=key)print (chat)
正常返回如下:
1 cache=None verbose=False callbacks=None callback_manager=None tags=None metadata=None client=<class 'openai.api_resources.chat_completion.ChatCompletion'> model_name='gpt-3.5-turbo' temperature=0.0 model_kwargs={} openai_api_key='OPENAI_API_KEY' openai_api_base='' openai_organization='' openai_proxy='' request_timeout=None max_retries=6 streaming=False n=1 max_tokens=None tiktoken_model_name=None
返回参数说明:
model_name:所要使用的模型,默认为 ‘gpt-3.5-turbo’,参数设置与 OpenAI 原生接口参数设置一致。
temperature:温度系数,取值同原生接口。
openai_api_key:OpenAI API key,如果不使用环境变量设置 API Key,也可以在实例化时设置。
openai_proxy:设置代理,如果不使用环境变量设置代理,也可以在实例化时设置。
streaming:是否使用流式传输,即逐字输出模型回答,默认为 False。
max_tokens:模型输出的最大 token 数,意义及取值同上。
6)LangChain Template配置prompt Template即模板,是LongChain中的一种固定的Prompt格式。可以在Template中填入自定义的任务来便捷的完成个性化任务的Prompt设置。
1、构造一个个性化 Template:Template写法固定格式,可以较大程度发挥模型性能。
1 2 3 4 5 6 7 8 9 10 11 12 from langchain.prompts import ChatPromptTemplate"""Translate the text \ that is delimited by triple backticks \ into a Chinses. \ text: ```{text}``` """
2、针对模型调用 format 方法,将 template 转化为模型输入的形式
1 2 3 4 5 6 "Today is a nice day." print (message)
转化的格式是专用于调用类似于 ChatGPT 的模型格式 的数据类型
3、使用template格式数据调用chatgpt
1 2 3 4 print (response)
参考:提示模板 | 🦜️🔗 Langchain
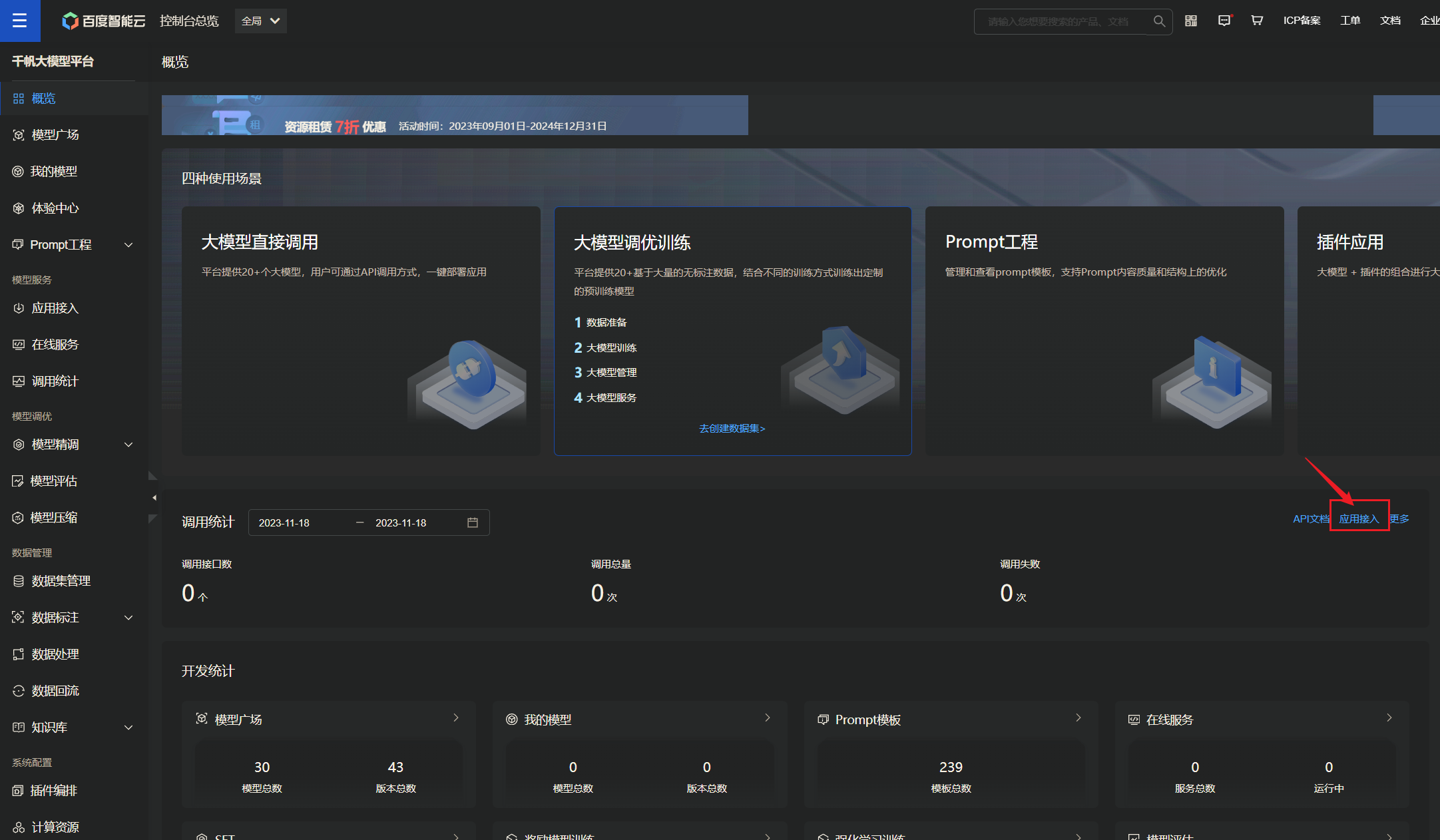
3.2、文心大模型API调用 1)文心key获取 进入百度云千帆大模型平台 ,应用接入:
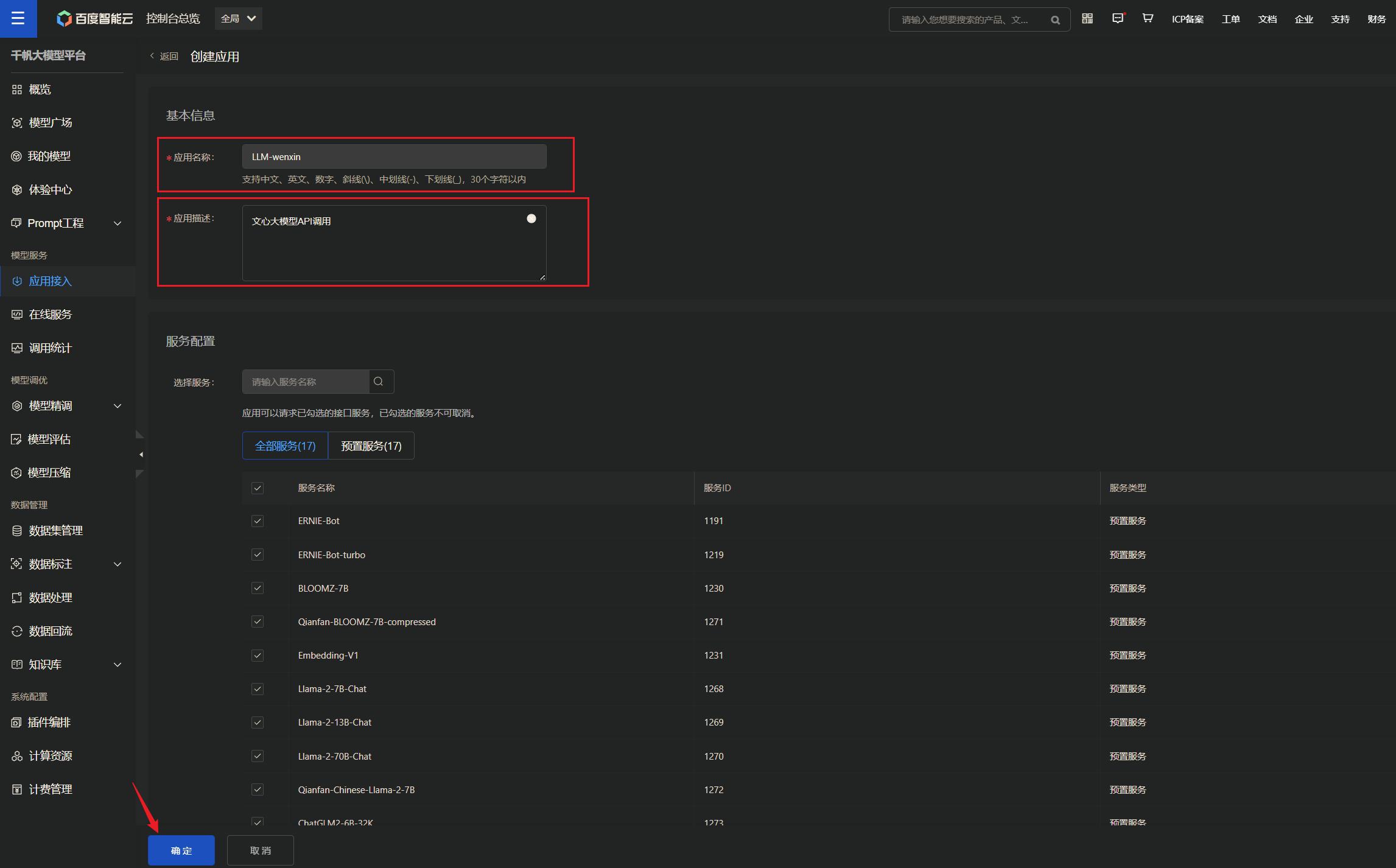
创建应用(需要账号已经实名制) :
填写应用基本信息,确定进入下一页:
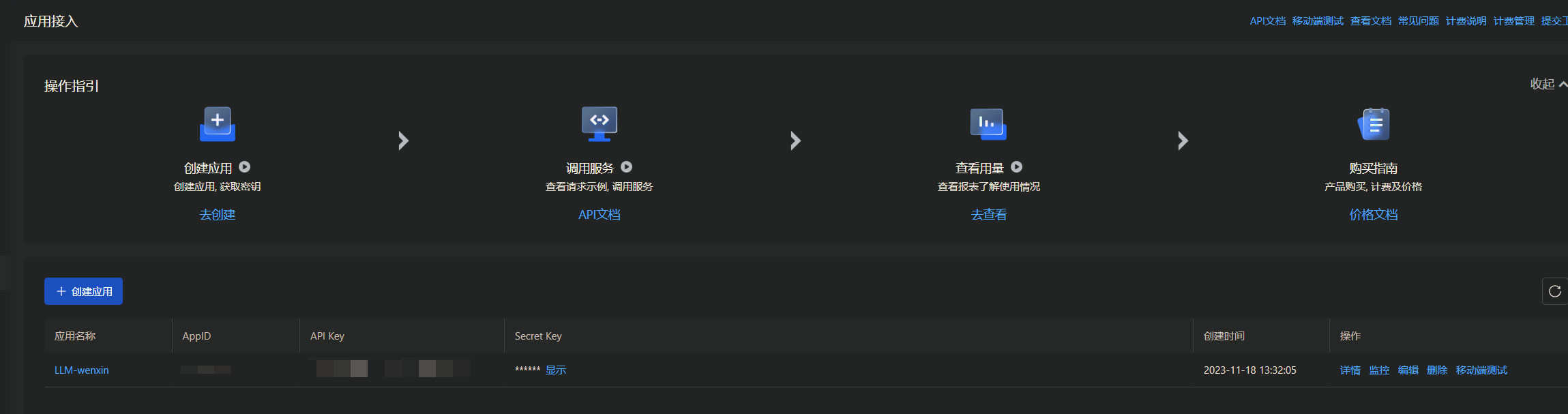
创建之后就可以在应用页面查看到我们刚建的应用,其中会展示我们想要的AppID、API Key、Secret Key:后续需要使用到API Key、Secret Key。
2)API原生调用 获取access_token:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import requestsimport jsondef get_access_token ():""" 使用 API Key,Secret Key 获取access_token,替换下列示例中的应用API Key、应用Secret Key """ "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={api_key}&client_secret={secret_key}" "" )'Content-Type' : 'application/json' ,'Accept' : 'application/json' "POST" , url, headers=headers, data=payload)return response.json().get("access_token" )
正常返回如下,通过access_token访问文心大模型:
调用文心原生API:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def get_wenxin (prompt ):""" 通过access_token调用文心一言模型 :param prompt:用户输入内容 :return:输出结果 """ "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant?access_token={access_token}" "messages" : ["role" : "user" ,"content" : "{}" .format (prompt)'Content-Type' : 'application/json' "POST" , url, headers=headers, data=payload)print (js["result" ])
调用模型(默认调用的是ERNIE-Bot-turbo模型):
1 2 3 4 5 6 7 8 def main ():"关于NLP" )if __name__ == "__main__" :
调用正常返回如下:
注意:文心大模型,免费用户1天只能调用1次,尝试多次,需购买token。
注:文心API调用与OpenAI相似,但没有system prompt的配置,仅支持 user、assistant 。
3)使用LangChain自定义文心LLM—待完善 3.3、星火大模型API调用 科大讯飞旗下的一款大模型产品,侧重于中文内容,是一款典型的中文大模型。在国内与文心一言不分上下。
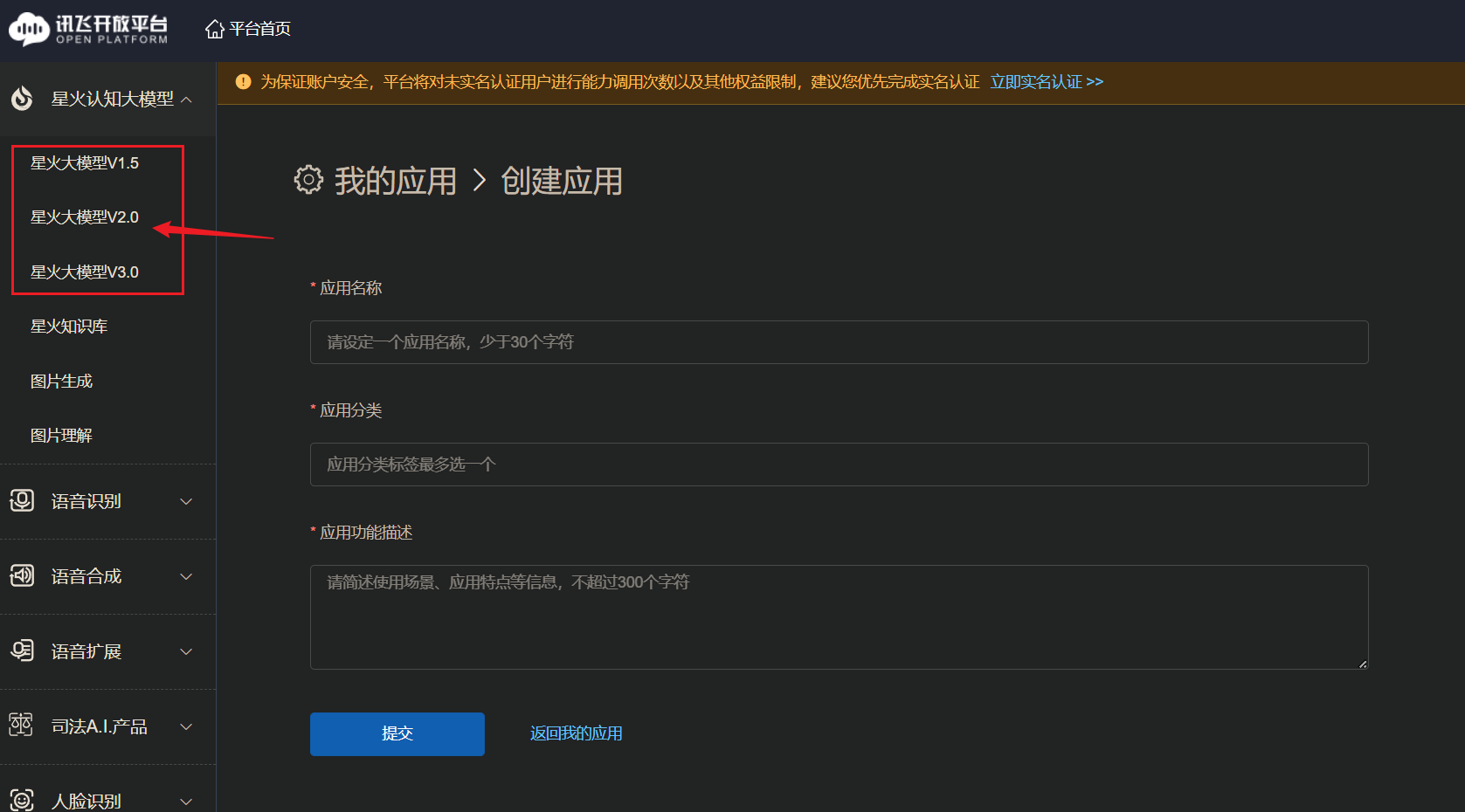
1)星火API申请 进入讯飞开放平台 申请:创建1个新应用,填写应用基本信息
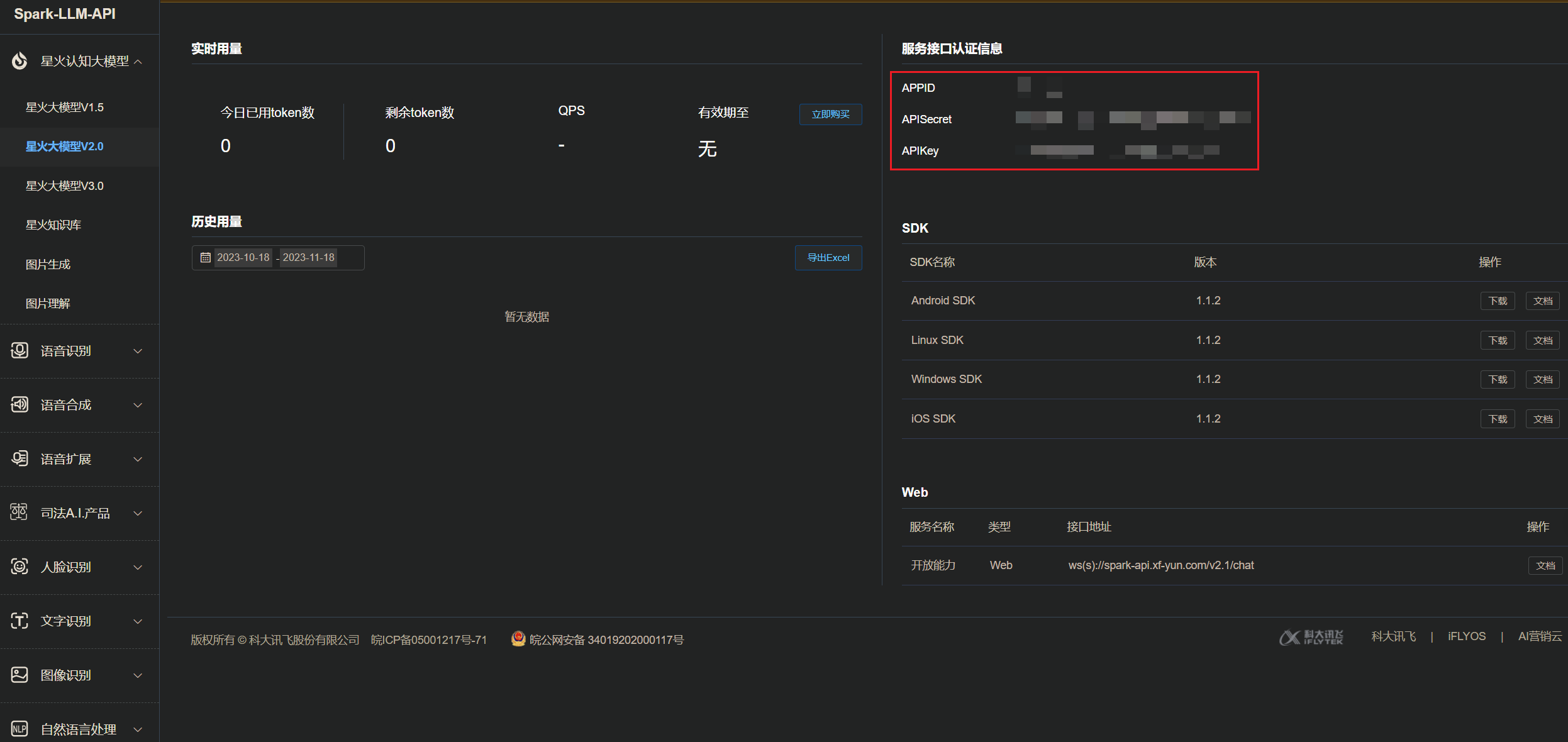
创建完了之后会在此处展示我们需要的APPID、APISecret、APIKey:
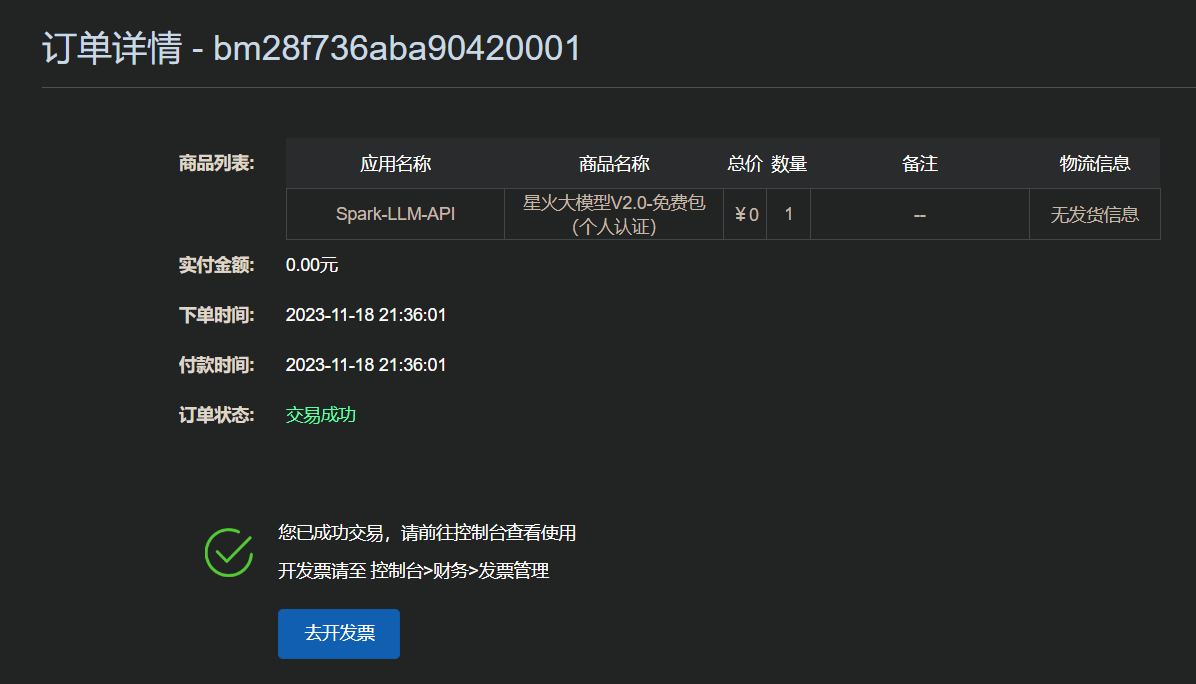
2)领取免费token 在应用控制台,实时用量,点击立即购买(必须要先实名):
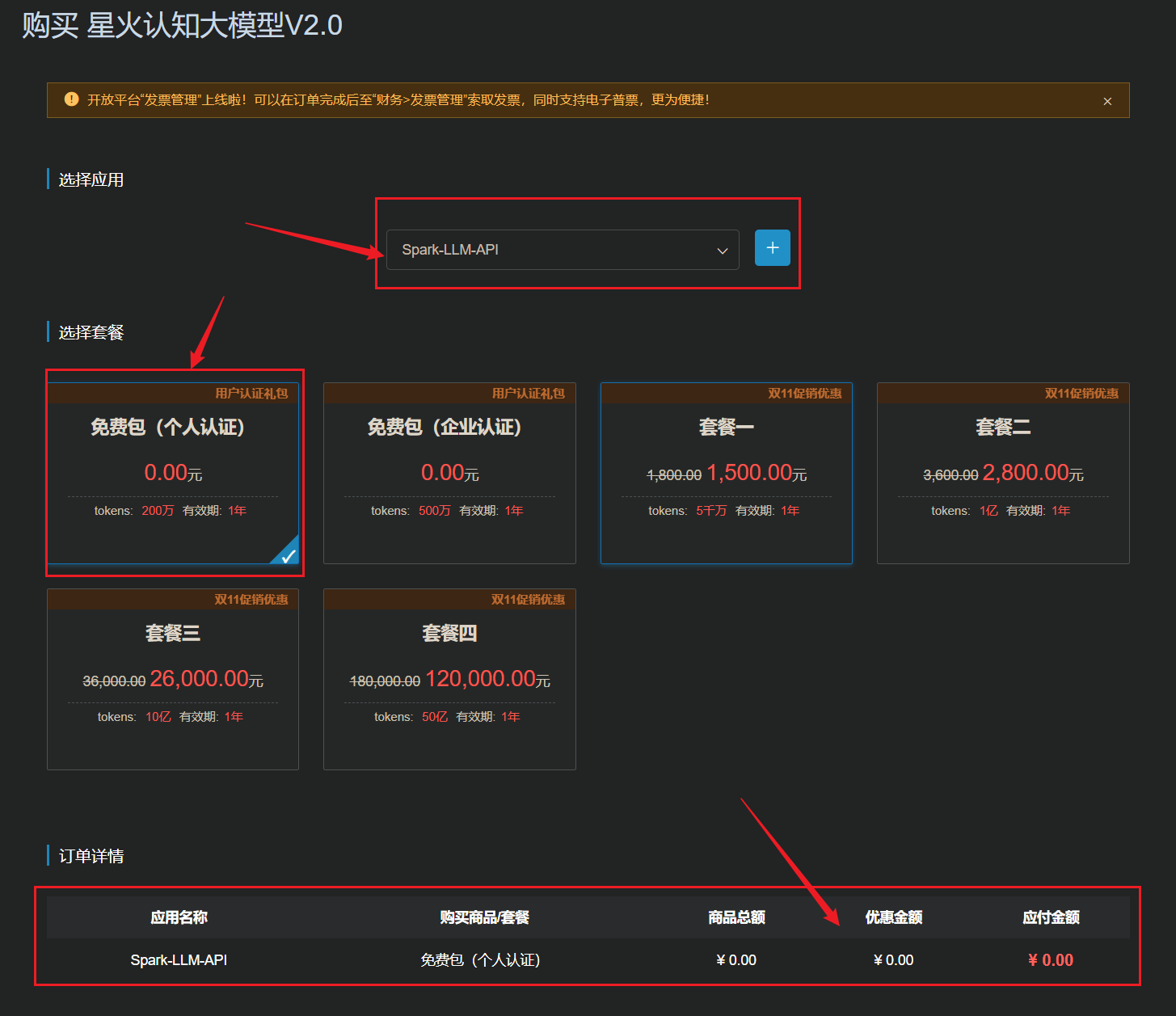
选择”免费包(个人认证)”:
选择OK之后,立即下单,就能成功购买了:
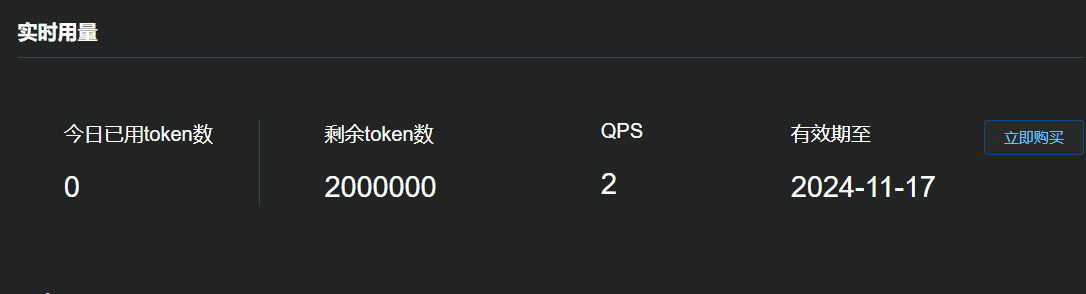
免费token额度会同步刷新:
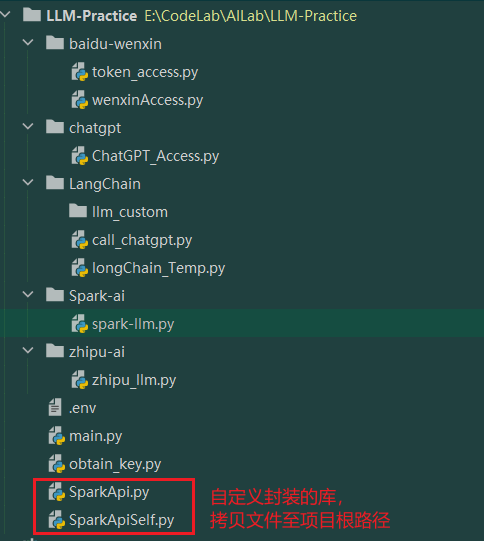
3)星火API调用 3.1)Spark相关库配置 由于星火 API 需要通过 WebSocket 进行连接,相对麻烦,这一步需要将SparkApi.py、SparkApiSelf.py两各个文件放置于项目根目录:
源文件,从datawhale仓库路径取:https://github.com/datawhalechina/llm-universe/tree/main/notebook/C2%20%E8%B0%83%E7%94%A8%E5%A4%A7%E6%A8%A1%E5%9E%8B%20API
3.2)Spark API调用 完整调用代码,调用的传参和文心类似,均为列表类型。其中要根据实际申请的星火大模型的版本来配置domain、Spark_url:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import SparkApi"APPID" "APISecret" "APIKey" "generalv2" "ws://spark-api.xf-yun.com/v2.1/chat" def get_text (role, content, text = [] ):"role" ] = role"content" ] = contentreturn text"user" , "你好" )print (question)
成功调用如下:
3.4、智谱GLM API调用 GLM为智谱AI与清华大学共同合作开发的一款认知大模型,为新一代通用大模型,接下来将展开实现GLM API的调用过程。
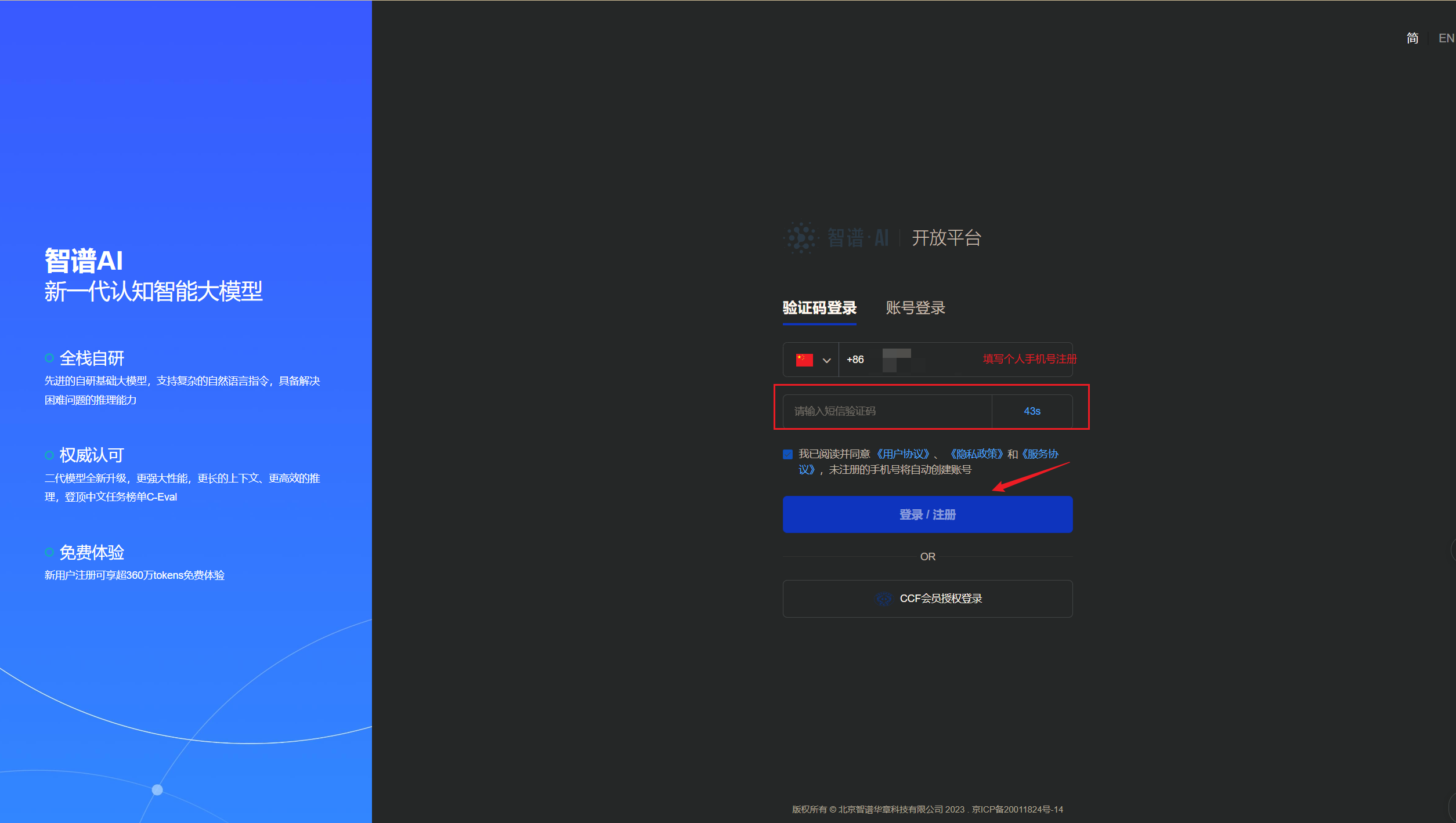
1)GLM API申请 进入智谱AI开放平台 :
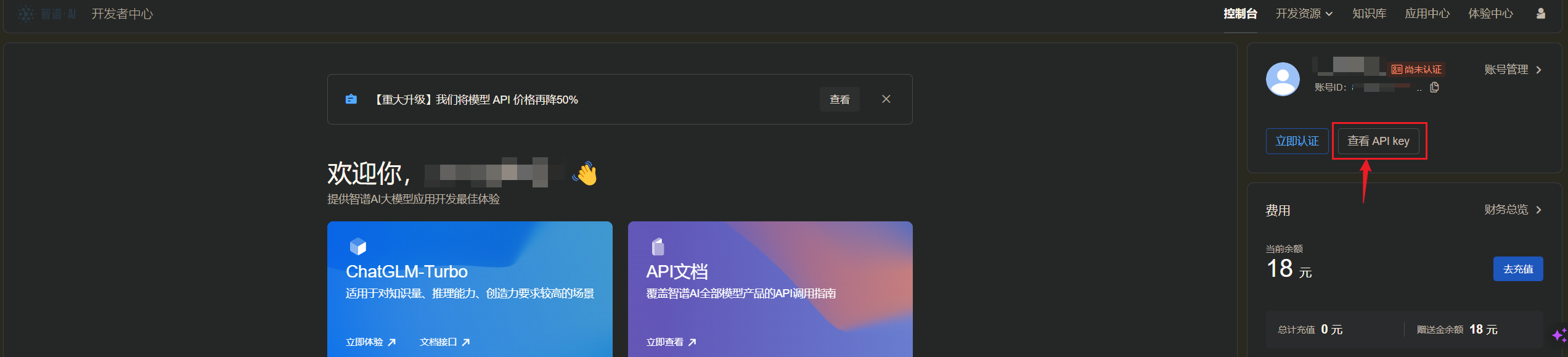
进入查看API Key,开始创建API Key:初始账号会存在一个系统默认的key,并且存在赠送的18元token额度
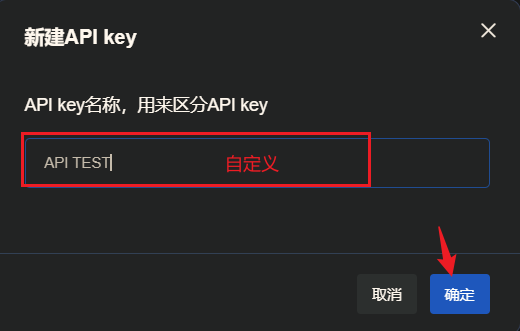
新建一个新的Key:
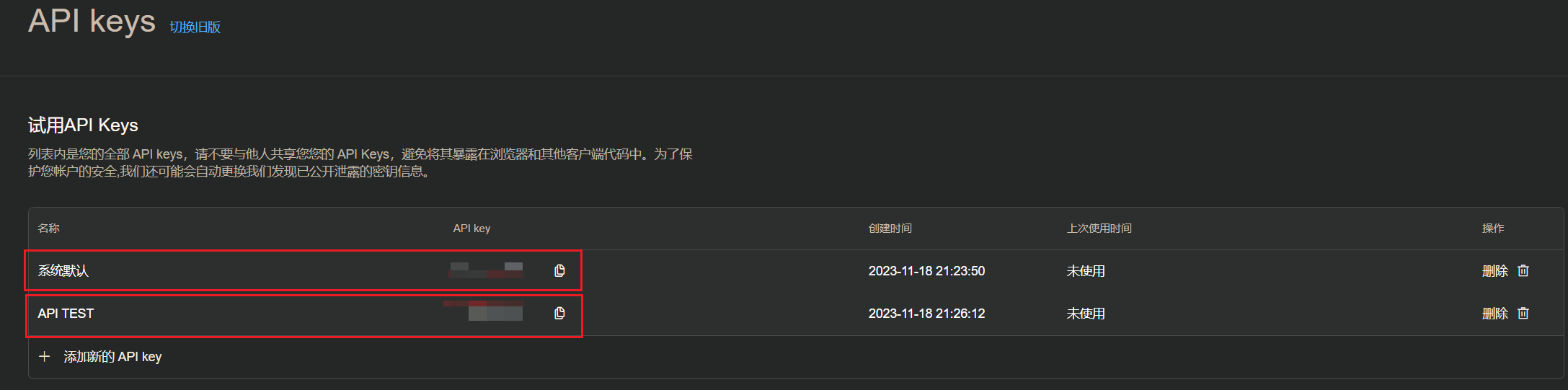
之后会存在两个API Key:一个自己新建的Key,一个系统默认的Key
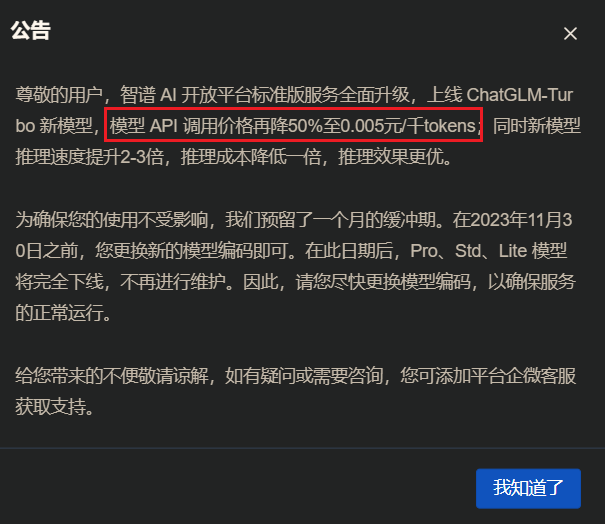
API价格:
2)调用智谱大模型API 智谱AI支持SDK 和原生 HTTP来调用模型,本节以SDK为主:
环境中安装配置示例中的所需第三方库
2.1)安装zhipu库 1 pip install zhipuai -i https://pypi.tuna.tsinghua.edu.cn/simple/
在第2章中,已经将环境提前准备好了,这里执行指令可以做个检查:
2.2)API调用 分为下面几段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import zhipuai"zhipu_key" "chatglm_std" def get_text (role, content, text = [] ):"role" ] = role"content" ] = contentreturn text"user" , "你好" )print (question)
调用AI:
1 2 3 4 5 6 print (response)
调用成功结果如下:
常用传入参数介绍:
prompt (list): 调用对话模型时,将当前对话信息列表作为提示输入给模型; 按照 {“role”: “user”, “content”: “你好”} 的键值对形式进行传参; 总长度超过模型最长输入限制后会自动截断,需按时间由旧到新排序。temperature (float): 采样温度,控制输出的随机性,必须为正数取值范围是:(0.0,1.0],不能等于 0,默认值为 0.95 值越大,会使输出更随机,更具创造性;值越小,输出会更加稳定或确定。top_p (float): 用温度取样的另一种方法,称为核取样。取值范围是:(0.0, 1.0) 开区间,不能等于 0 或 1,默认值为 0.7。模型考虑具有 top_p 概率质量 tokens 的结果。例如:0.1 意味着模型解码器只考虑从前 10% 的概率的候选集中取 tokens。request_id (string): 由用户端传参,需保证唯一性;用于区分每次请求的唯一标识,用户端不传时平台会默认生成return_type (string): 用于控制每次返回内容的类型,空或者没有此字段时默认按照 json_string 返回。json_string 返回标准的 JSON 字符串。text 返回原始的文本内容
注: 不建议同时调整temperature和 top_p ,根据具体场景单独调整1个即可。接口文档:https://open.bigmodel.cn/dev/api
参考文档:https://datawhalechina.github.io/llm-universe/#/C2/4.%20%E8%B0%83%E7%94%A8%E8%AE%AF%E9%A3%9E%E6%98%9F%E7%81%AB
 :
: