LLM笔记4:LLM向量数据库构建
本文最后更新于:2023年11月21日 晚上
1、知识库的数据
1.1、需要什么数据库?
如何来构建一个适用于LLM的数据库,不同于传统的关系型数据库SQL那些,LLM中所存储的数据均为向量格式,在LLM中进行运算的也是以向量作为语料。也正是这个特殊点,LLM的数据库也称之为向量数据库。当前的方案是使用LangChain架构来构建出一个向量数据库,在LangChain中已经集成了30多个向量数据库工具,考虑到轻巧加载快捷的特点,这里使用Chroma向量数据库作为首选。
1.2、数据的处理过程
明确了构建工具,接下来是构建流程。构建的过程,首先是语料收集和处理:
数据语料,可以使用不同类型的格式文件,常见的如PDF文本文件、MP4视频文件、MD文本文件等。
将这些文件经过处理之后,可以存储到向量数据库中,最终目的是要将这些数据转换为向量的格式。具体要经过下面的一些处理过程:
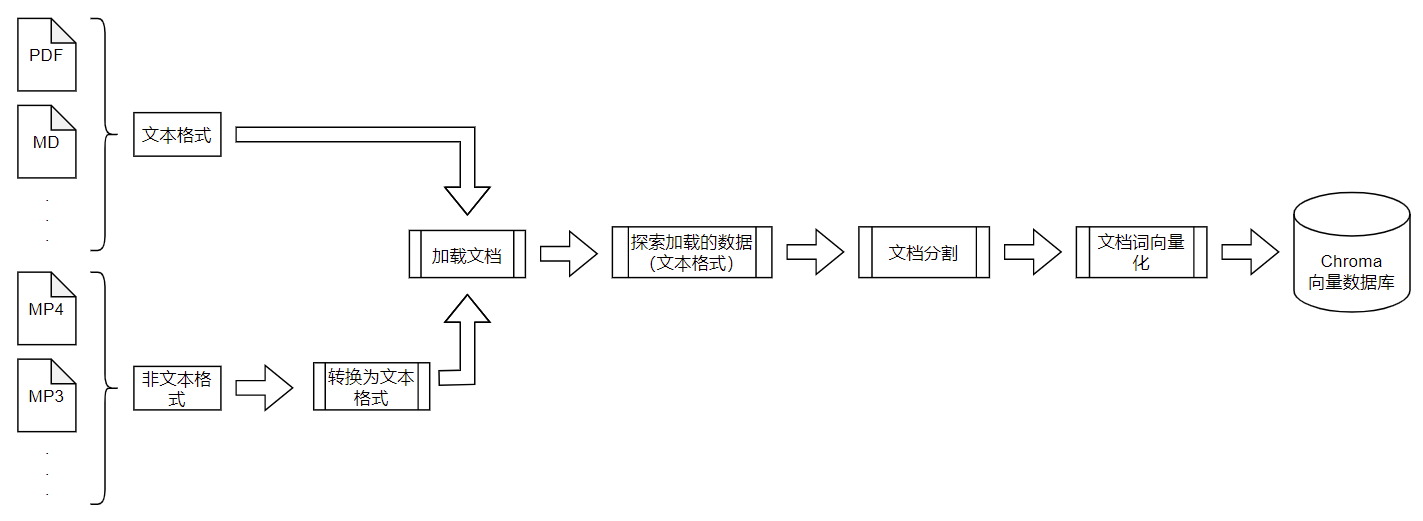
方便处理的是文本类型的结构化数据,非结构化数据需要经过转化处理才能使用。
2、向量数据库构建
2.1、Chroma认识
Chroma向量数据库,用来专门检索向量数据即Embedding的一种数据库系统,在LangChain集成,这里涉及到embedding一些知识点,参考下面的内容,暂时不做梳理:
embedding的认识:
调用智谱embedding:
向量数据库中的数据形式,其中每个向量代表一个数据项,每个向量,可以是文本、数字、或者图像亦或是视频等其他格式的数据类型。通过建立向量数据库,能够对其中的数据建立高效的索引,加速检索过程和存储过程的效率。
2.2、通过向量数据库进行检索
在向量数据库中可以使用多种检索方式,有几个典型的检索:
1)相似度检索:以相似度即词的相关性进行检索
2)MMR检索:最大边际相关性(MMR,Maximum marginal relevance)。主要目的是在进行相似度检索的同时,增加内容的丰富度。
后续还有链锁式问答、结合Prompt提问过程处理,后续进行扩展。
3、项目数据库构建
实践流程,将具体的文件处理成文档词向量化,存储到Chroma向量数据库中,从而建立我们的LLM应用数据源。按照第一章流程来建立项目数据库。
注:Embedding的类型有许多,根据使用的LLM大模型来实践。